http://www.oracle.com/partners/en/knowledge-zone/applications/042831.html - Oracle Hyperion Knowledge Zone
http://www.oracle.com/partners/secure/engage-with-oracle/026361 - Oracle EMEA Partner Community for BI & EPM
http://www.oracle.com/partners/secure/engage-with-oracle/product-focus/029689.htm - Oracle Unified Method (OUM)
http://ilearning.oracle.com/ilearn/en/learner/jsp/category.jsp?categoryid=26435 - Oracle University Courses in Category Hyperion EPM
23 дек. 2010 г.
10 дек. 2010 г.
Запуск calc скриптов
Предлагаю 2 варианта запуска calc скриптов Essbase c параметрами через MaxL:
1. Используем подстановочные переменные (substitution variables ):
Создаем переменные:
alter application Sample add variable 'vScenario';
alter application Sample add variable 'vVersion';
или через EAS консоль:

Создаем в кубе Sample.Basic calc скрипт Agg_test.csc:
2. Используем возможности MaxL
Создаем MaxL Agg_test2.mxl:
3. Дополнительная информация.
Чем отличается скрипт в ' ' от скрипта в " "?
Не используйте в кодах измерений Outline символы ".", пробел и прочие спец. символы т.к. это приводит к усложнению написания скриптов т.к. необходимо применять символ '/'.
Если не поставить "/" перед "." и не взять код элемента, в котором есть пробел в кавычки, MaxL будет сообщать об ошибке.
Не правильно:
1. Используем подстановочные переменные (substitution variables ):
Создаем переменные:
alter application Sample add variable 'vScenario';
alter application Sample add variable 'vVersion';
или через EAS консоль:

Создаем в кубе Sample.Basic calc скрипт Agg_test.csc:
FIX (&vScenario, &vEntity) CALC DIM (Account, Period, Entity...) ENDFIXСоздаем MaxL Agg_test.mxl:
login admin identified by 'password' on localhost; spool on to "Maxl.log"; set timestamp on; set inputScenario = $1; set inputVersion = $2; alter application Sample set variable "vScenario" "$inputScenario"; alter application Sample set variable "vVersion" "$inputVersion"; execute calculation Sample.Basic.Agg_test; exit;Запускаем MaxL:
essmsh Agg_test.mxl BUD VR_Work
2. Используем возможности MaxL
Создаем MaxL Agg_test2.mxl:
login admin identified by 'password' on localhost; spool on to "Maxl.log"; set timestamp on; set inputScenario = $1; set inputVersion = $2; execute calculation " FIX ($inputScenario, $inputVersion) CALC DIM (Account, Period, Entity...) ENDFIX " on Sample.Basic; exit;Запускаем MaxL:
essmsh Agg_test2.mxl BUD VR_WorkВ итоге результат будет достигнут аналогично п.1, но в данном случае не надо создавать отдельный calc скрипт и подстановочные переменные.
3. Дополнительная информация.
Чем отличается скрипт в ' ' от скрипта в " "?
vYear=FY10 Execute Calculation "FIX ($vYear)" on Sample.Basic /* правильно */ Execute Calculation 'FIX ($vYear)' on Sample.Basic /* не правильно */В результате код первого скрипта будет - FIX (FY10), а код второго скрипта останется без изменения - FIX ($vYear), что приведет к ошибке. Т.е. если данные заключены в одинарные кавычки, то подстановка переменных не происходит.
Не используйте в кодах измерений Outline символы ".", пробел и прочие спец. символы т.к. это приводит к усложнению написания скриптов т.к. необходимо применять символ '/'.
Если не поставить "/" перед "." и не взять код элемента, в котором есть пробел в кавычки, MaxL будет сообщать об ошибке.
Не правильно:
Execute Calculation " FIX ($vYear, Moscow.01, "Moscow 02") CALC DIM (Account, Period) ENDFIX" on Sample.BasicПравильно:
Execute Calculation "FIX ($vYear, Moscow/.01, /"Moscow 02/") CALC DIM (Account, Period) ENDFIX" on Sample.BasicПравильно, но подстановка невозможна:
Execute Calculation ' FIX (FY10, "Moscow.01", "Moscow 02") CALC DIM (Account, Period) ENDFIX' on Sample.Basic
23 нояб. 2010 г.
XREF vs Partitions
Наверное на каждом проекте мы сталкиваемся с необходимостью обмениваться данными между кубами. Для этого в Essbase есть специальные инструменты: XREF, Replicated Partition, Transparent Partition.
Рассмотрим их по порядку.
XREF - cамый простой и безболезненый способ получить данные из другого куба, минусы - это низкая производительность и проблемы с созданием блоков (в 11.1.2 добавили @XWRITE). Не рекомендую использовать XREF в формулах динамических элементов (Dynamic Calc) т.к. на больших срезах это приводит к потере производительности.
Пример использования: получить значение по ограниченному срезу.
Replicated partition - если вам надо копировать блоки нижнего уровня 1:1 без всяких расчетов и транформаций, то что надо. Есть функциональность по переносу только обновленных данных.
Пример использования: передать данные по статье A по нижнему уровню из Source в Target.
Дополнительная информация - http://essbase.ru/2010/10/replicated-partitions/
Transparent partition - мощный инструмент для маштабирования. Если сравнивать с Oracle RDB - это аналог view или updateable view. Имеет ряд особенностей связанных с тем, что данные не хранятся в Target кубе, а подтягиваются налету. Пример: в Target по данным из партиции невозможно создать блоки, выгрузить данные с помощью Dataexport и т.д. Но что очень интерестно - из Target можно обновлять данные в Source!
Пример использования: разделение приложения на Факт и План с партицией по сценарию, разделение по странам, версиям и т.д.
Дополнительная информация - http://essbase.ru/2010/10/transparent-partition/
Сравнительная таблица:
 * в 11.1.2 добавлена функция @XWRITE, которая позволяет записывать данные в Target
* в 11.1.2 добавлена функция @XWRITE, которая позволяет записывать данные в Target
** данные изменяются только после запуска обновления партиции или вызова XREF
*** write-back функциональность
Пример MaxL создание Replicated partition и ее обновление:
P.S. Выгрузка и загрузка данных с помощью Dataexport, Report script, MDX в данном случае не рассматривались
P.S.S. Source - это куб источник. Target - куб получатель данных.
P.S.S.S. Если производительности XREF не хватает, смотрите в сторону партиций. Если партиции не устраивают, то используйте Dataexport
Рассмотрим их по порядку.
XREF - cамый простой и безболезненый способ получить данные из другого куба, минусы - это низкая производительность и проблемы с созданием блоков (в 11.1.2 добавили @XWRITE). Не рекомендую использовать XREF в формулах динамических элементов (Dynamic Calc) т.к. на больших срезах это приводит к потере производительности.
Пример использования: получить значение по ограниченному срезу.
Replicated partition - если вам надо копировать блоки нижнего уровня 1:1 без всяких расчетов и транформаций, то что надо. Есть функциональность по переносу только обновленных данных.
Пример использования: передать данные по статье A по нижнему уровню из Source в Target.
Дополнительная информация - http://essbase.ru/2010/10/replicated-partitions/
Transparent partition - мощный инструмент для маштабирования. Если сравнивать с Oracle RDB - это аналог view или updateable view. Имеет ряд особенностей связанных с тем, что данные не хранятся в Target кубе, а подтягиваются налету. Пример: в Target по данным из партиции невозможно создать блоки, выгрузить данные с помощью Dataexport и т.д. Но что очень интерестно - из Target можно обновлять данные в Source!
Пример использования: разделение приложения на Факт и План с партицией по сценарию, разделение по странам, версиям и т.д.
Дополнительная информация - http://essbase.ru/2010/10/transparent-partition/
Сравнительная таблица:
** данные изменяются только после запуска обновления партиции или вызова XREF
*** write-back функциональность
Пример MaxL создание Replicated partition и ее обновление:
create or replace replicated partition 'RP_ACT'.'RP' area '"ACT"' sourcearea1 to 'RP_BUD'.'RP' area '"ACT"' targetarea1; refresh replicated partition RP_ACT.RP to RP_BUD.RP at 'localhost' all data; refresh replicated partition RP_ACT.RP to RP_BUD.RP at 'localhost' updated data;
P.S. Выгрузка и загрузка данных с помощью Dataexport, Report script, MDX в данном случае не рассматривались
P.S.S. Source - это куб источник. Target - куб получатель данных.
P.S.S.S. Если производительности XREF не хватает, смотрите в сторону партиций. Если партиции не устраивают, то используйте Dataexport
10 нояб. 2010 г.
Берегись пустых блоков
Агрегирует ли Essbase пустые блоки? Сейчас узнаем.
1. Очищаем куб Sample.Basic и смотрим количество существующих блоков:
 2. Вводим число 1.
2. Вводим число 1.
 3. Меняем 1 на #Missing
3. Меняем 1 на #Missing
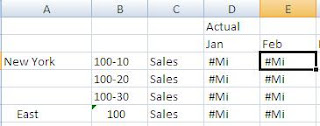 4. Смотрим количество существующих блоков:
4. Смотрим количество существующих блоков:
SET AGGMISSG ON;
CALC ALL;
6. Смотрим количество существующих блоков:
Вывод - независимо от того есть ли данные в какой-либо ячейке или нет Essbase агрегирует данные (создает блоки верхнего уровня), что приводит к увеличению времени расчета и увеличению размера БД.
Что делать - удалить пусты блоки можно командой "CLEARBLOCK Empty;"
Как еще бороться с ненужными данными:
P.S. Еще один пример скрипта и его краткого лога, где агрегация работает неэффективно
1. Очищаем куб Sample.Basic и смотрим количество существующих блоков:



- Existing level 0 blocks - 1
- Existing upper-level blocks - 0
SET AGGMISSG ON;
CALC ALL;
6. Смотрим количество существующих блоков:
- Existing level 0 blocks - 1
- Existing upper-level blocks - 8!!!
Вывод - независимо от того есть ли данные в какой-либо ячейке или нет Essbase агрегирует данные (создает блоки верхнего уровня), что приводит к увеличению времени расчета и увеличению размера БД.
Что делать - удалить пусты блоки можно командой "CLEARBLOCK Empty;"
Как еще бороться с ненужными данными:
- Удаляйте нули (часто пользователи вместо #Missing вносят "0")
- Правильно удаляйте ненужные срезы командами CLEARBLOCK или CLEARDATA (не фиксируйте плотные элементы).
- Выгружайте нулевой срез в реляционную таблицу и анализируйте данные (часто много ненужных цифр залипают на Begbalance, архивных статьях и т.д.)
P.S. Еще один пример скрипта и его краткого лога, где агрегация работает неэффективно
/* параметр логировая */
SET MSG SUMMARY;
/* удаляем все блоки*/
CLEARBLOCK ALL;
/* создаем один блок c Jan = 100*/
SET CREATENONMISSINGBLK ON;
FIX ("New York", "100-10", "Sales", "Actual")
"Jan" = 100;
ENDFIX
SET CREATENONMISSINGBLK OFF;
/* агрегируем Feb */
SET AGGMISSG ON;
FIX ("Feb")
CALC DIM ("Measures", "Product", "Market", "Scenario");
ENDFIX/* удалили */ Clearing all data blocks from [(ALL)] partition Removed [9] data blocks /* создали один блок */ Calculating [ Year(Jan)] with fixed members [Sales; 100-10; New York; Actual] Create Blocks on Equations: [Enabled] Create Non #Missing Blocks: [Enabled] Total Block Created: [1.0000e+000] Blocks /* создали 7 блоков */ Calculating [ Measures, Scenario, Product, Market, with fixed members [Year(Feb)] Aggregate #Missing values: [Enabled] Total Block Created: [7.0000e+000] BlocksЯ сделал запись в Jan, а агрегировал по Feb - все равно блоки создаются. Это конечно же не ошибка, а особенность работы Essbase, которую надо учитывать.
8 нояб. 2010 г.
Hyperion Roadmap 2011
Hyperion Essbase 11.1.3
Hyperion EPM 11.1.3
- Full integration with BI Foundation installation
- Oracle Business Intelligence Essbase Integrator
- Fusion Middleware Integration
- Active-Active high availability clustering
- User-defined objects
- ASO calc extensions
- Storage optimization
- Metadata integration
- Fast-restructure of ASO outline changes
- BSO restructure performance improvements
- Parallel-calc performance improvements
- Enterprise Manager replace EAS admin functionality
- Unify capabilities in Studio and EAS
- Essbase as a Studio Source
Hyperion EPM 11.1.3
- New Project Planning module
- New Chart of Accounts Manager module
- Portfolio wide Enterprise 2.0 adoption
- Hyperion Financial Management
- Configurable Dimensionality
- Financial Close
- Variance Monitoring
- Disclosure Management
- Collaborative document authoring
- Smart Rounding & Footing
- Hyperion Planning
- PSB Commitment control
- Valid combinations
- ASO Integration
2 нояб. 2010 г.
Парсер логов calcmgrlaunch.log
Предлагаю вашему вниманию парсер логов расчетов Calc Manager 11.1.1.x. Данный парсер ищет окончание расчета и выводит результат в удобном виде.
1. Скачиваем файл Excel с макросом BR_log.xls
2. Копируем файл /logs/calcmgr/calcmgrlaunch.log на локальный компьютер
3. Открываем BR_log.xls и жмем кнопку "Open calcmgrlaunch.log"

3. Наслаждаемся видом :)

P.S. Файл лога обязательно должен называться calcmgrlaunch.log
1. Скачиваем файл Excel с макросом BR_log.xls
2. Копируем файл /logs/calcmgr/calcmgrlaunch.log на локальный компьютер
3. Открываем BR_log.xls и жмем кнопку "Open calcmgrlaunch.log"

3. Наслаждаемся видом :)

P.S. Файл лога обязательно должен называться calcmgrlaunch.log
24 окт. 2010 г.
Dynamic Calc Members (BSO)
Когда же лучше всего использовать динамические элементы в BSO-кубах?
1. Плотные (dense) измерения
Использовать нужно всегда т.к. это ведет к уменьшению размера блока => размер куба будет меньше => производительность расчетов улучшится, производительность извлечения данных (retrieve) меняется незначительно +/- 1%! Необходимо только избегать динамических элементов с комплексными формулами т.е. когда при расчете формулы необходимо смотреть в другие блоки. Кандидаты на изменения типа храния на динамический - родители или любой элемент с простой формулой.
Примеры (Период и Статья - плотные, Страна - разряженные):
2. Разряженные (sparse) измерения
Использовать можно только для уменьшения времени агрегации, при этом ухудшается время извлечения данных (retrieve).
Пример:
3. Выводы
Динамические элементы - это хорошая возможность улучшить производительность, но конечно же со своей спецификой.
1. Плотные (dense) измерения
Использовать нужно всегда т.к. это ведет к уменьшению размера блока => размер куба будет меньше => производительность расчетов улучшится, производительность извлечения данных (retrieve) меняется незначительно +/- 1%! Необходимо только избегать динамических элементов с комплексными формулами т.е. когда при расчете формулы необходимо смотреть в другие блоки. Кандидаты на изменения типа храния на динамический - родители или любой элемент с простой формулой.
Примеры (Период и Статья - плотные, Страна - разряженные):
- Кварталы (Q1, Q2, Q3, Q4) - можно сделать динамическими
- (+) Acc_Total: Выручка итого
(+) Acc_01: Выручка A
(+) Acc_02: Выручка Б
Статью Acc_Total можно сделать динамической
- Статья: Prof_01 = Acc_01 / Acc_Total - можно сделать динамической (расчет в пределах одного блока)
- Статья: Prof_Russia = Acc_Total->Entity_Russia - нужно делать хранимой т.к. при распаковке любого блока (расчете или просмотре) Essbase будет смотреть на блок по стране Entity_Russia
2. Разряженные (sparse) измерения
Использовать можно только для уменьшения времени агрегации, при этом ухудшается время извлечения данных (retrieve).
Пример:
- (+) Entity_Russia - dynamic
(+) Entity_Msc - store
(+) Entity_Spb - store
Если пользователь строит запрос по Entity_Russia, то серверу необходимо прочитать 2 дополнительных блока по Msc и Spb
- Когда элемент участвует в выгрузках (report script, dataexport)
- Когда элемент участвует в партициях
- Когда элемент участвует в создании блоков (datacopy с динамических элементов не работает)
- Когда на элементе хранят расчетные данные (аллокации, элиминации)
3. Выводы
Динамические элементы - это хорошая возможность улучшить производительность, но конечно же со своей спецификой.
Подписаться на:
Сообщения (Atom)